#ETCD 一文入门
KV 服务,创建,更新,获取和删除键值对。 监视,监视键的更改。 租约,消耗客户端保持活动消息的基元。 锁,etcd 提供分布式共享锁的支持。 选举,暴露客户端选举机制。 https://doczhcn.gitbook.io/etcd/index
https://juejin.cn/post/6844904031186321416
#概念术语
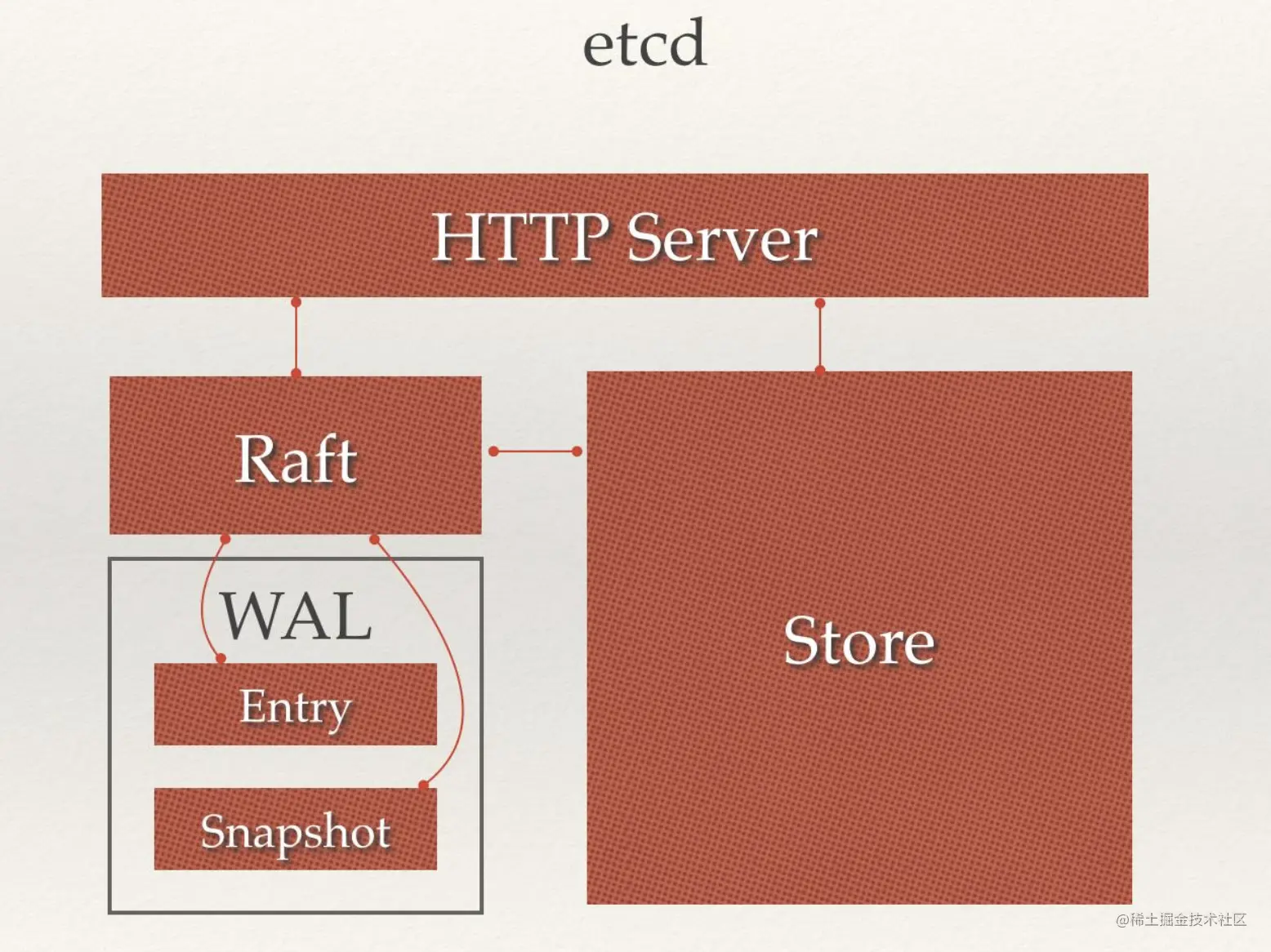
Raft:etcd所采用的保证分布式系统强一致性的算法。
Node:一个Raft状态机实例。
Member: 一个etcd实例。它管理着一个Node,并且可以为客户端请求提供服务。
Cluster:由多个Member构成可以协同工作的etcd集群。
Peer:对同一个etcd集群中另外一个Member的称呼。
Client: 向etcd集群发送HTTP请求的客户端。
WAL:预写式日志,etcd用于持久化存储的日志格式。
snapshot:etcd防止WAL文件过多而设置的快照,存储etcd数据状态。
Proxy:etcd的一种模式,为etcd集群提供反向代理服务。
Leader:Raft算法中通过竞选而产生的处理所有数据提交的节点。
Follower:竞选失败的节点作为Raft中的从属节点,为算法提供强一致性保证。
Candidate:当Follower超过一定时间接收不到Leader的心跳时转变为Candidate开始竞选。
Term:某个节点成为Leader到下一次竞选时间,称为一个Term。
Index:数据项编号。Raft中通过Term和Index来定位数据。
#数据读写顺序
为了保证数据的强一致性,etcd集群中所有的数据流向都是一个方向,从 Leader (主节点)流向 Follower,也就是所有 Follower 的数据必须与 Leader 保持一致,如果不一致会被覆盖。
用户对于etcd集群所有节点进行读写
读取:由于集群所有节点数据是强一致性的,读取可以从集群中随便哪个节点进行读取数据 写入:etcd集群有leader,如果写入往leader写入,可以直接写入,然后然后Leader节点会把写入分发给所有Follower,如果往follower写入,然后Leader节点会把写入分发给所有Follower
#leader选举
假设三个节点的集群,三个节点上均运行Timer(每个Timer持续时间是随机的),Raft算法使用随机Timer来初始化Leader选举流程,第一个节点率先完成了Timer,随后它就会向其他两个节点发送成为Leader的请求,其他节点接收到请求后会以投票回应然后第一个节点被选举为Leader。
成为Leader后,该节点会以固定时间间隔向其他节点发送通知,确保自己仍是Leader。有些情况下当Follower们收不到Leader的通知后,比如说Leader节点宕机或者失去了连接,其他节点会重复之前选举过程选举出新的Leader。
#判断数据是否写入
etcd认为写入请求被Leader节点处理并分发给了多数节点后,就是一个成功的写入。那么多少节点如何判定呢,假设总结点数是N,那么多数节点 Quorum=N/2+1。关于如何确定etcd集群应该有多少个节点的问题,上图的左侧的图表给出了集群中节点总数(Instances)对应的Quorum数量,用Instances减去Quorom就是集群中容错节点(允许出故障的节点)的数量。
所以在集群中推荐的最少节点数量是3个,因为1和2个节点的容错节点数都是0,一旦有一个节点宕掉整个集群就不能正常工作了。