#一致性 Hash 算法 Java 实现 — G.Fukang's Blog
本文由 简悦 SimpRead 转码, 原文地址 gongfukangee.github.io
一致性 Hash 算法 Java 实现(虚拟节点 + 实体节点)及性能对比
一致性 Hash 算法 Java 实现(虚拟节点 + 实体节点)及性能对比
假设现在我们需要使用 Redis 存储图片资源,存储的格式为键值对,key 为图片名称,value 为该图片所在文件服务器的路径,我们需要根据文件名查询该文件所在文件服务器上的路径,假设数据有 100W,部署 4 台缓存服务器,每台服务器大约存储 25W 数据,如果按照随机分配的规则,某一条数据可能会存储在任何一台缓存服务器上,这样,假设查找 beijing.jpg 图片,则最坏需要 4 次查询才能找到,效率很低。
如果在取数据时能够提前知道某条数据存储在哪个服务器上,则仅需要一次查询就能找到,效率提高很多。这种方案可以通过余数 Hash 来实现,在存储数据时,首先得到数据 key 值的 HashCode,然后对缓存服务器数量取余,得到的余数就是要存储的服务器编号。由于 HashCode 是具有随机性的,因此余数 Hash 算法可以保证缓存数据在整个服务器集群中比较均匀分布。假设图片 beijing.jpg 的 hashcode 值是 10,则存放时放在 10 % 4 = 2 编号为 2 的缓存服务器上,下次取 beijing.jpg 时,可以直接根据 hashcode 值,去编号为 2 的缓存服务器取,只需要一次查询。
这种方法虽然提升了性能,但是还是存在一些缺陷,主要体现在服务器数量发生变动时,缓存的位置就需要发生改变。假设现在 4 台服务器已经满足不了我们的需求,需要添加到 5 台服务器,则还是以 beijing.jpg 为例,之前存储的时候存储在编号为 2 的缓存服务器,现在在取图片时,10 % 5 = 0 ,根据 hashcode 值计算出的缓存服务器编号为 0,无法命中缓存。也就说说缓存服务器的数量发生变动时,大部分缓存一定时间内是失效的,在缓存重建的这段时间内,所有的请求都会从数据库获取数据,容易导致缓存雪崩问题。
一致性 Hash 算法通过构建环状的 Hash 空间替线性 Hash 空间的方法解决了这个问题,整个 Hash 空间被构建成一个首位相接的环。
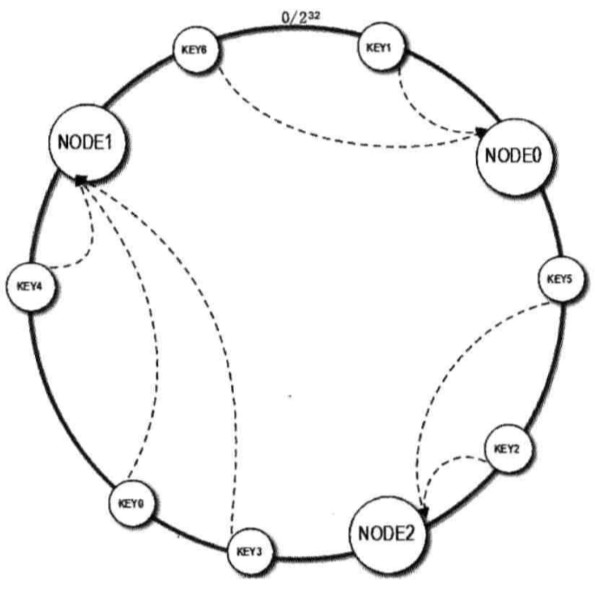 其具体的构造过程为:
其具体的构造过程为:
- 先构造一个长度为 2^32 的一致性 Hash 环
- 计算每个缓存服务器的 Hash 值,并记录,这就是它们在 Hash 环上的位置
- 对于每个图片,先根据 key 的 hashcode 得到它在 Hash 环上的位置,然后在 Hash 环上顺时针查找距离这个 Key 的 Hash 值最近的缓存服务器节点,这就是该图片所要存储的缓存服务器
当缓存服务器需要扩容的时候,只需要将新加入缓存服务器的 Hash 值放入一致性 Hash 环中,由于 Key 是顺时针查找距离其最近的节点,因此新加入的几点只影响整个环中的一小段。加入新节点 NODE3 后,原来的 Key 大部分还能继续计算到原来的节点,只有 Key3、Key0 从原来的 NODE1 重新计算到 NODE3,这样就能保证大部分被缓存数据还可以命中。当节点被删除时,其他节点在环上的映射不会发生改变,只是原来打在对应节点的 key 现在会转移到顺时针方向的下一个节点上。
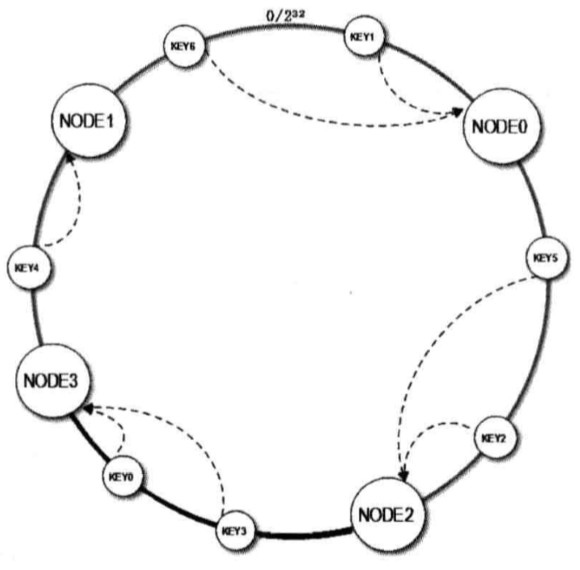
新加入的节点 NODE3 只影响了原来的节点 NODE1,也就是说一部分原来需要访问 NODE1 的缓存数据现在需要访问 NODE3(概率上是 50%)但是原来的节点 NODE0 和 NODE2 不受影响,这就意味着 NODE0 和 NODE2 缓存数据量和负载压力是 NODE1 与 NODE3 的两倍。
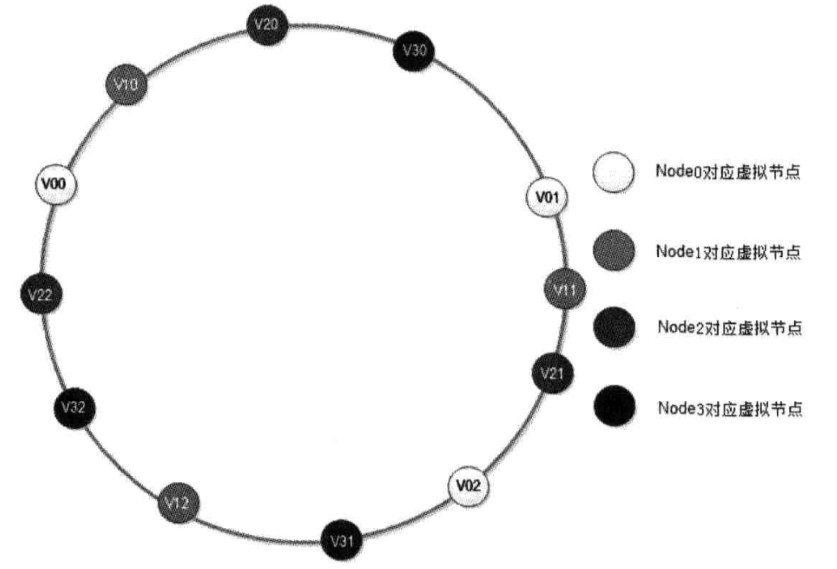
为了解决这个问题,最好的办法就是扩展整个环上的节点数量,可以将每台物理缓存服务器虚拟为一组虚拟缓存服务器,使得 Hash 环在空间上的分割更加均匀。
这样只是将虚拟节点的 Hash 值放置在 Hash 环上,在查找时,首先根据 Key 值找到环上的虚拟节点,然后再根据虚拟节点找到真实额缓存服务器。虚拟节点的数目足够多,就会使得节点在 Hash 环上的分布更加随机化,也就是增加或者删除一台缓存服务器时,都会较为均匀的影响原来集群中已经存在的缓存服务器。
在 Dubbo 中如果同一环境下服务提供者的数量大于 1,就会出现服务消费者要选择哪个 Provider 进行调用的问题。为了避免集群中部分服务器压力过大,另一些服务器比较空闲的情况,就需要通过负载均衡,让负载 “均摊” 到不同的机器上。Dubbo 中就提供了基于一致性 Hash 的负载均衡算法,只是将缓存服务器替换成 Provider,根据 Provider 和 Consumer 的 IP 地址获取 hashcode。
虽然一致性 Hash 算法已经十分完善,但是还是有很多不足的地方
- Hash 环上的节点非常多或者更新频繁时,查询效率比较低下
- 整个 Hash 环需要一个服务路由来做负载均衡,存在单点问题
针对这两个问题,Redis 在实现自己的分布式集群方案时,采用了基于 P2P 结构的哈希槽算法
- 使用哈希槽
- Redis Cluster 通过分片的方式将整个缓存划分为 16384 个槽,每个缓存节点就相当于 Hash 换上的一个节点,接入集群时,所有实例都将均匀占有这些哈希槽,当需要查询一个 Key 是,首先根据 Key 的 hashcode 对 16384 取余来得到 Key 属于哪个槽,并映射到缓存实例上。
- 为了方便描述,将 16384 抽象为 20 个哈希槽单位,在增加缓存实例时,假设原来有 4 个节点,分配的哈希槽为 0-4,5-9,10-14,15-19 现在增加一个节点,Redis Cluster 的做法是将之前每台服务器上的一部分哈希槽移动到第四个节点上,更新后的哈希槽分配为 1-4,6-9,11-14,16-19 第四个节点为 0,5,10,15。删除也是同理
- 去中心化
- 每个节点都保存有完整的哈希槽 - 节点的映射表,也就是说,每个节点都知道自己拥有哪些哈希槽,以及某个确定的哈希槽究竟对应着哪个节点。
- 无论向哪个节点发出寻找 Key 的请求,该节点都会通过求余计算该 Key 究竟存在于哪个哈希槽,并将请求转发至该哈希槽所在的节点。
一致性 Hash 算法首先需要考虑的问题就是:构造一个长度为 2^32 的整数环,根据节点名称的 Hash 值将服务器节点放置在这个 Hash 环上。
算出所有待加入的数据结构的节点名称的 Hash 值放入一个数组中,然后使用排序算法将其从小到大进行排序,最后将排序后的数据放入 List 中。之后,待路由的节点,只需要在 List 中找到第一个 Hash 值比它大的服务器节点就可以了。比如服务器节点的 Hash 值是 [0,2,4,6,8,10],待路由的节点是 7,则只需要找到第一个比 7 大的整数,也就是 8,就是我们要找的最终需要路由过去的服务器节点。
直接使用 Arrays#sort() 时间复杂度为 O(NLogN),则总的时间复杂度为:
- 最好情况,一次找到 O(1) + O(NLogN)
- 最坏情况,最后一次找到 O(N) + O(NLogN)
则总的时间复杂度为 O(NLogN)
由于排序比较消耗性能,那么可以选择不排序,直接遍历的方式:
- 服务器节点不排序,其 Hash 值全部放到一个 List 中
- 等待路由的节点,算出其 Hash 值,由于指明了顺时针,因此遍历 List,比待路由节点 Hash 值大的算出差值并记录,比待路由节点 Hash 值小的忽略
- 算出所有的差值之后,最小的那个,就是最终需要路由过去的节点
现在算下时间复杂度:
- 最好的情况是只有一个服务器节点的 Hash 值大于带路由节点的 Hash 值,O(N) + O(1)
- 最坏的情况是所有服务器节点的 Hash 值都大于待路由节点的 Hash 值,时间复杂度是 O(N) + (N)
则总的时间复杂度为 O(N)
选用红黑树的原因
- 红黑树主要的作用是用于存储有序的数据,因此相当于省略了排序这步骤,效率很高
- JDK 里面提供了红黑树的代码实现 TreeMap 和 TreeSet
- 红黑树提供了一个方法 ceilingEntry(Integer key) 可以直接获取 key 右边的第一个节点,如果节点为空,表示已经到尾,则直接取树的第一个节点
时间复杂度分析:O(logN)
服务器节点一般用字符串表示,比如 192.168.1.1,根据字符串得到其 Hash 值,所以一个重要的问题就是 Hash 值重新计算,首先看下直接使用 String#hashCode() 的结果
public static void main(String[] args) {
System.out.println("192.168.0.0:111 的哈希值:" + Math.abs("192.168.0.0:111".hashCode()));
System.out.println("192.168.0.1:111 的哈希值:" + Math.abs("192.168.0.1:111".hashCode()));
System.out.println("192.168.0.2:111 的哈希值:" + Math.abs("192.168.0.2:111".hashCode()));
System.out.println("192.168.0.3:111 的哈希值:" + Math.abs("192.168.0.3:111".hashCode()));
System.out.println("192.168.0.4:111 的哈希值:" + Math.abs("192.168.0.4:111".hashCode()));
}
/** output **/
192.168.0.0:111 的哈希值:771739798
192.168.0.1:111 的哈希值:770816277
192.168.0.2:111 的哈希值:769892756
192.168.0.3:111 的哈希值:768969235
192.168.0.4:111 的哈希值:768045714
明显可以看到,在 [0,2^23 - 1] 这个大区间中,5 和 HashCode 值仅仅分布在一个小区间,导致某个服务器的负载会特别大。因此需要一种新的计算 Hash 值的方法, 这种重新计算 Hash 值的算法有很多,比如 CRC32_HASH、FNV1_32_HASH、KETAMA_HASH 等,其中 KETAMA_HASH 是默认的 Reids 推荐的一致性 Hash 算法,用别的 Hash 算法也可以,比如 FNV1_32_HASH 算法的计算效率就会高一些,这里选用 FNV1_32_HASH 算法
没有虚拟节点,就会出现前文提到的 Hash 环数据倾斜问题,某种程度上来说,这样就失去了负载均衡的意义,因为负载均衡的目的就是为了使得目标服务器均分所有的请求
可以通过引入虚拟节点减小负载均衡问题,查阅资料了解到,物理服务器很少,则需要更多的虚拟节点;反之,物理服务器比较多,虚拟节点就少一点。
构造虚拟节点需要考虑两个问题:
- 一个真实的节点如何对应多个虚拟节点
- 虚拟节点找到后如何还原成真实的节点
参考其他博客有个简单的方法,给每个真实节点机上后缀再取 Hash 值,比如:”192.168.0.0:111” 就可以变成 “192.168.0.0:111&&VN0”,”192.168.0.0:111&&VN1”,”192.168.0.0:111&&VN2”,”192.168.0.0:111&&VN3”,还原的时候只需要从头截取字符串到 ”&&“ 位置就可以了
通用接口
public interface LoadBalancer {
// 添加服务器节点
public void addServerNode(String serverNodeName);
// 删除服务器节点
public HashMap<String, String> delServerNode(String serverNodeName);
// 选择服务器节点
public String selectServerNode(String requestURL);
}
使用 FNVI_32_HASH 算法计算 Hash 值
public class GetHashCode {
private static final long FNV_32_INIT = 2166136261L;
private static final int FNV_32_PRIME = 16777619;
public int getHashCode(String origin) {
final int p = FNV_32_PRIME;
int hash = (int)FNV_32_INIT;
for (int i = 0; i < origin.length(); i++) {
hash = (hash ^ origin.charAt(i)) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
hash = Math.abs(hash);
return hash;
}
}
请求 IP 构造
public class IPAddressGenerate {
public String[] getIPAddress(int num) {
String[] res = new String[num];
Random random = new Random();
for (int i = 0; i < num; i++) {
res[i] = String.valueOf(random.nextInt(256)) + "." + String.valueOf(random.nextInt(256)) + "."
+ String.valueOf(random.nextInt(256)) + "." + String.valueOf(random.nextInt(256)) + ":"
+ String.valueOf(random.nextInt(9999));
}
return res;
}
}
请求在每台服务器上分布的数量方差计算
public class Analysis {
// <节点,服务器>
public double analysis(HashMap<String, String> map) {
Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
// 计数 map <Server, Count>
ConcurrentHashMap<String, Integer> countMap = new ConcurrentHashMap<>();
while (iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
String server = entry.getValue();
if (countMap.containsKey(server)) {
countMap.put(server, countMap.get(server) + 1);
} else {
countMap.put(server, 1);
}
}
Collection<Integer> values = countMap.values();
Iterator<Integer> val = values.iterator();
int count = 0;
int[] res = new int[values.size()];
while (val.hasNext()) {
res[count] = val.next();
}
return variance(res);
}
// 求方差
private static double variance(int[] arr) {
int m = arr.length;
double sum = 0;
for (int i = 0; i < m; i++) {
sum += arr[i];
}
double dAve = sum / m;
double dVar = 0;
for (int i = 0; i < m; i++) {
dVar += (arr[i] - dAve) * (arr[i] - dAve);
}
return dVar / m;
}
}
public class SortedMapWithoutVirtualNode implements LoadBalancer {
private static Logger logger = LoggerFactory.getLogger(SortedMapWithoutVirtualNode.class);
private TreeMap<Integer, String> treeMapHash;
@Override
public void addServerNode(String serverNodeName) {
int hash = new GetHashCode().getHashCode(serverNodeName);
treeMapHash.put(hash, serverNodeName);
}
@Override
public void delServerNode(String serverNodeName) {
int hash = new GetHashCode().getHashCode(serverNodeName);
treeMapHash.remove(hash);
logger.info("服务器节点:{} 下线", serverNodeName);
}
@Override
public String selectServerNode(String requestURL) {
int hash = new GetHashCode().getHashCode(requestURL);
// 向右寻找第一个 key
Map.Entry<Integer, String> subEntry= treeMapHash.ceilingEntry(hash);
// 设置成一个环,如果超过尾部,则取第一个点
subEntry = subEntry == null ? treeMapHash.firstEntry() : subEntry;
return subEntry.getValue();
}
// 构建 Hash 环
public SortedMap<Integer, String> buildHash(TreeMap<Integer, String> treeMap) {
this.treeMapHash = treeMap;
return treeMapHash;
}
}
测试代码
public class SortedMapWithoutVirtualNodeTest {
private static Logger logger = LoggerFactory.getLogger(SortedMapWithoutVirtualNodeTest.class);
private static SortedMapWithoutVirtualNode sortedMapWithoutVirtualNode = new SortedMapWithoutVirtualNode();
// Hash 环
private static SortedMap<Integer, String> treeMapHash;
// 服务器总数
private static final int SERVERS_NUM = 100;
// 待加入 Hash 环的服务器列表
private static ArrayList<String> servers = new ArrayList<>();
private static void init() {
// 构造服务器数据
for (int i = 0; i < SERVERS_NUM; i++) {
StringBuilder stringBuilder = new StringBuilder();
servers.add(stringBuilder.append("192.168.0.").append(String.valueOf(i)).toString());
}
// 构建 Hash 环
treeMapHash = sortedMapWithoutVirtualNode.buildHash(new TreeMap<Integer, String>());
// 将服务器添加到 Hash 环中
for (int i = 0; i < SERVERS_NUM; i++) {
sortedMapWithoutVirtualNode.addServerNode(servers.get(i));
}
}
public static void main(String[] args) {
init();
// 请求节点
String[] nodes = new IPAddressGenerate().getIPAddress(10000);
// <节点,服务器>
HashMap<String, String> map = new HashMap<>();
for (int i = 0; i < nodes.length; i++) {
// 选择服务器
String serverIP = sortedMapWithoutVirtualNode.selectServerNode(nodes[i]);
// 记录服务器信息
map.put(nodes[i], serverIP);
}
logger.info("初始方差: " + new Analysis().analysis(map));
}
}
public class SortedMapWithVirtualNode implements LoadBalancer {
private static Logger logger = LoggerFactory.getLogger(SortedMapWithVirtualNode.class);
private TreeMap<Integer, String> treeMapHash;
@Override
public void addServerNode(String serverNodeName) {
int hash = new GetHashCode().getHashCode(serverNodeName);
treeMapHash.put(hash, serverNodeName);
// logger.info("服务器节点:{} 上线", serverNodeName);
}
@Override
public void delServerNode(String serverNodeName) {
int hash = new GetHashCode().getHashCode(serverNodeName);
treeMapHash.remove(hash);
logger.info("服务器节点:{} 下线", serverNodeName);
}
@Override
public String selectServerNode(String requestURL) {
int hash = new GetHashCode().getHashCode(requestURL);
// 向右寻找第一个 key
Map.Entry<Integer, String> subEntry = treeMapHash.ceilingEntry(hash);
// 设置成一个环,如果超过尾部,则取第一个点
subEntry = subEntry == null ? treeMapHash.firstEntry() : subEntry;
String VNNode = subEntry.getValue();
return VNNode.substring(0, VNNode.indexOf("&&"));
}
// 构建 Hash 环
public SortedMap<Integer, String> buildHash(TreeMap<Integer, String> treeMap) {
this.treeMapHash = treeMap;
return treeMapHash;
}
}
测试代码
public class SortedMapWithVirtualNodeTest {
private static Logger logger = LoggerFactory.getLogger(SortedMapWithVirtualNodeTest.class);
private static SortedMapWithVirtualNode sortedMapWithVirtualNode = new SortedMapWithVirtualNode();
// Hash 环
private static SortedMap<Integer, String> treeMapHash;
// 服务器总数
private static final int SERVERS_NUM = 100;
// 每台服务器需要设置的虚拟节点数
private static final int VIRTUAL_NODES = 10;
// 待加入 Hash 环的服务器列表
private static ArrayList<String> serverList = new ArrayList<>();
private static void init() {
// 构造服务器数据
for (int i = 0; i < SERVERS_NUM; i++) {
String s = new StringBuilder().append("192.168.0.").append(String.valueOf(i)).toString();
serverList.add(s);
}
// 构建 Hash 环
treeMapHash = sortedMapWithVirtualNode.buildHash(new TreeMap<Integer, String>());
// 将服务器的虚拟节点添加到 Hash 环中
for (String s : serverList) {
for (int i = 0; i < VIRTUAL_NODES; i++) {
String VNNode = s + "&&VN" + String.valueOf(i);
sortedMapWithVirtualNode.addServerNode(VNNode);
}
}
}
public static void main(String[] args) {
init();
// <节点,服务器>
HashMap<String, String> map = new HashMap<>();
// 请求节点
String[] nodes = new IPAddressGenerate().getIPAddress(10000);
// <节点,服务器>
for (int i = 0; i < nodes.length; i++) {
// 选择服务器
String serverIP = sortedMapWithVirtualNode.selectServerNode(nodes[i]);
// 记录服务器信息
map.put(nodes[i], serverIP);
}
logger.info("虚拟节点,初始方差: " + new Analysis().analysis(map));
}
}
模拟 1000 个请求,100 台服务器,每台服务器 100 个虚拟节点,比较方差为:
- 不带虚拟节点:143.98
- 带虚拟节点为:51.32
参考其他博客,使用 FNVI_32_HASH 算法计算 Hash 值,在服务器增加后,缓存的命中率为 78% 左右
#评论
#评论 1 · 2023-02-22T08:15:20.819000Z
https://github.com/golang/groupcache/blob/master/consistenthash/consistenthash.go