#ProtoStuff 序列化java对象
序列化后存json 问题
- 速度慢,cpu占用高
- 存储空间大,浪费资源
决定使用 ProtoStuff 代替 Jackson 框架 ProtoStuff 是一种基于 Google Protocol Buffers(protobuf)协议的序列化和反序列化库,它可以将 Java 对象序列化为二进制数据并进行网络传输或存储,也可以将二进制数据反序列化为 Java 对象
由于不用写proto文件,这里序列化 反序列化 需要 注意java entity|dao|bean 增删改字段后的兼容问题 网易这块原理是 增加一个schema的缓存,带version .
Schema,这是一个类似于数据库 DDL 结构的东西,它定义了序列化对象的类的结构信息,有哪些字段,字段的顺序是怎么样的,怎样序列化,怎样反序列化。
这个schema通过RuntimeSchema进行懒创建并缓存
所以可以一直调用RuntimeSchema.getSchema(),这个方法是线程安全的
schema = RuntimeSchema.getSchema(clazz);
Java 的 getDeclaredFields 方法返回的字段数组不是按照特定的顺序排列的。字段的顺序取决于具体的 JVM 实现以及编译器等因素。因此,在不使用 Tag 注解的时候,序列化的字段顺序是不固定的。如果在原有的字段中间随意插入一个字段,或者在合并代码的时候调换了字段的顺序,反序列化的数据不仅会错乱,很大概率还会报错。
- 方案1 : 用@Tag 注解来显式的声明字段序列化的顺序.
- 方案2: 自适应 ProtoStuff 的改造方案 https://xie.infoq.cn/article/84ab8e0e45be3e3736a11ebdb
#序列化
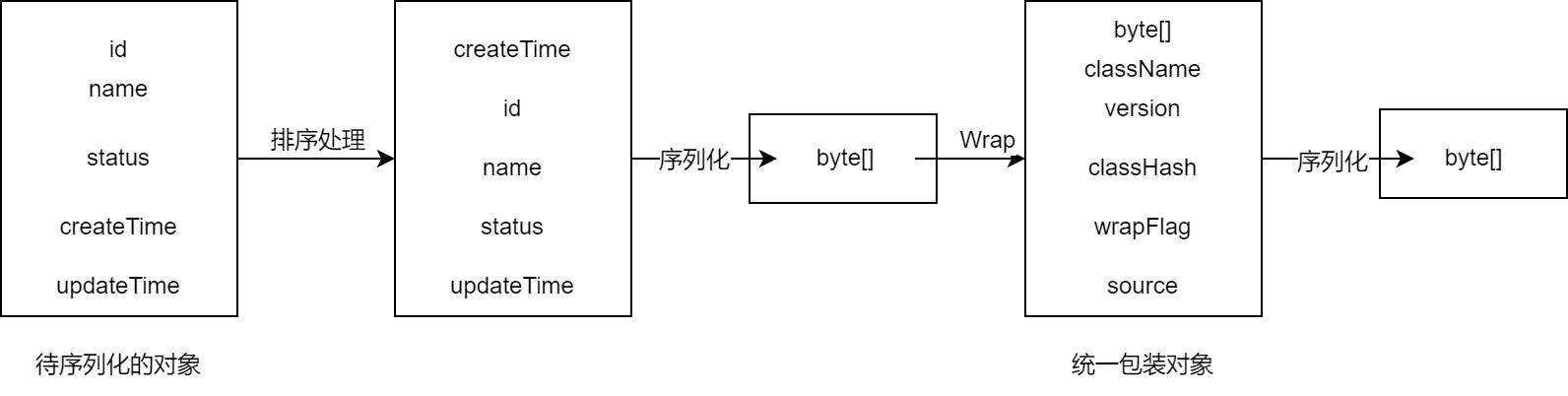
将 getDeclaredFields 方法获取到的当前类及其父类所有的字段,根据字段名称进行排序。
遍历排序后的字段列表,将字段转换成 ProtoStuff 需要的 Field 列表,再调用 RuntimeSchema 的构造方法新建一个对象。通过 RuntimeSchema 对象完成序列化操作,生成字节数组。
由于 ProtoStuff 的编码是 T-L-V 格式的,只存了对象字段的下标和具体的值,没有存完整的类路径,而且 spring-data-redis 反序列化的时候不知道目标对象的类型,因此还需要一个包装类来存储额外的信息。
对统一包装对象进行序列化,返回生成的字节数组。
将缓存对象的类结构信息缓存到 Redis 中,以便反序列化时使用。
#反序列化
将字节数组反序列化成通用的包装类。
从包装类中获取到源数据的类路径,版本号,字段哈希值。先判断源数据类是否是集合或者基本数据类型,如果是基本数据类型,直接返回 source 字段的内容。如果是集合类,判断本地版本号是否与包装类获取到的版本号一致,一致的时候返回 source 字段的内容。
源数据类型既不是集合也不是基本数据类型,获取本地对象的版本号,如果本地对象版本号大于缓存版本号,则将缓存数据淘汰掉。
如果本地对象的版本号和缓存中的版本号一致,就直接使用本地类进行转换,获取到 RuntimeSchema 进行反序列化。
如果本地对象的版本号小于缓存中的版本号,则需要根据类路径 + 缓存版本号 从 Redis 中获取到对应的类结构信息,将本地的字段进行重新排序,获取到和缓存数据对应的字段顺序值,再生成相应的 RuntimeSchema 进行反序列化。