#etcd 分布式 - 看图轻松了解 etcd
本文由 简悦 SimpRead 转码, 原文地址 segmentfault.com
用一些图示结合场景和文字轻松了解 etcd,文章是针对 etcd 初学者的,目的是让大家了解 etcd 是什么、主要在什么场景下使用、etcd 集群是怎么工作的以及创建集群时...
用一些图示结合场景和文字轻松了解 etcd,文章是针对 etcd 初学者的,目的是让大家了解 etcd 是什么、主要在什么场景下使用、etcd 集群是怎么工作的以及创建集群时应该如何选择集群的节点数。
etcd 是一个高可用强一致性的键值仓库在很多分布式系统架构中得到了广泛的应用,其最经典的使用场景就是服务发现。
作为一个受到 ZooKeeper 启发而催生的项目,它除了拥有与之类似的功能外,更专注于以下四点。
- 简单:易于部署,易使用。基于 HTTP+JSON 的 API 让你用 curl 就可以轻松使用。
- 安全:可选 SSL 客户认证机制。
- 快速:每个实例每秒支持一千次写操作。
- 可信:使用一致性 Raft 算法充分实现了分布式。
etcd 的场景默认处理的数据都是系统中的控制数据。所以 etcd 在系统中的角色不是其他 NoSQL 产品的替代品,更不能作为应用的主要数据存储。etcd 中应该尽量只存储系统中服务的配置信息,对于应用数据只推荐把数据量很小,但是更新和访问频次都很高的数据存储在 etcd 中。
#服务发现(Service Discovery)
服务发现要解决的是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务,要如何才能找到对方并建立连接。本质上来说,服务发现就是想要了解集群中是否有进程在监听 udp 或 tcp 端口,并且通过名字就可以查找和连接。要解决服务发现的问题,需要有下面三大支柱,缺一不可。
- 一个强一致性、高可用的服务存储目录。基于 Raft 算法的 etcd 就是一个强一致性高可用的服务存储目录。
- 一种注册服务和监控服务健康状态的机制。用户可以在 etcd 中注册服务,并且对注册的服务设置
key TTL,定时保持服务的心跳以达到监控健康状态的效果。 - 一种查找和连接服务的机制。通过在 etcd 指定的主题(由服务名称构成的服务目录)下注册的服务也能在对应的主题下查找到。
#etcd 的核心组件
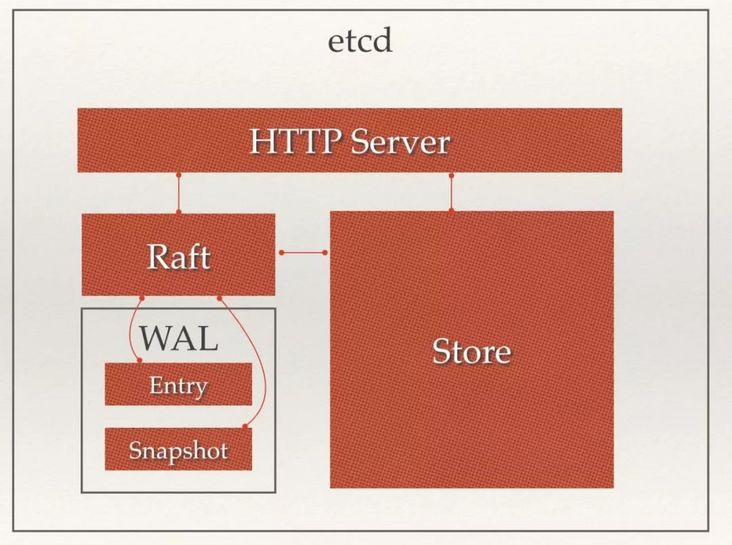
从 etcd 的架构图中我们可以看到,etcd 主要分为四个部分。
- HTTP Server:用于处理用户发送的 API 请求以及其它 etcd 节点的同步与心跳信息请求。
- Store:用于处理 etcd 支持的各类功能的事务,包括数据索引、节点状态变更、监控与反馈、事件处理与执行等等,是 etcd 对用户提供的大多数 API 功能的具体实现。
- Raft:Raft 强一致性算法的具体实现,是 etcd 的核心。
- WAL:Write Ahead Log(预写式日志),是 etcd 的数据存储方式。除了在内存中存有所有数据的状态以及节点的索引以外,etcd 就通过 WAL 进行持久化存储。WAL 中,所有的数据提交前都会事先记录日志。Snapshot 是为了防止数据过多而进行的状态快照;Entry 表示存储的具体日志内容。
通常,一个用户的请求发送过来,会经由 HTTP Server 转发给 Store 进行具体的事务处理,如果涉及到节点的修改,则交给 Raft 模块进行状态的变更、日志的记录,然后再同步给别的 etcd 节点以确认数据提交,最后进行数据的提交,再次同步。
#用户从集群中哪个节点读写数据?
为了保证数据的强一致性,etcd 集群中所有的数据流向都是一个方向,从 Leader (主节点)流向 Follower,也就是所有 Follower 的数据必须与 Leader 保持一致,如果不一致会被覆盖。
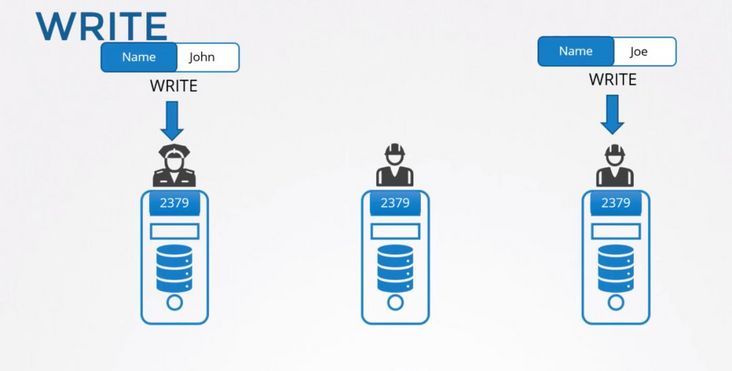
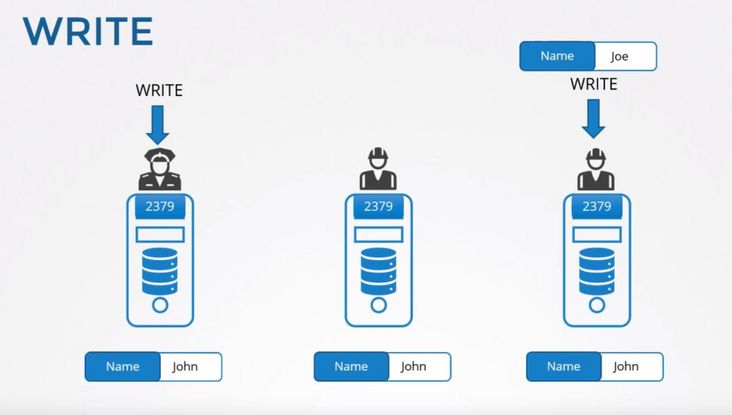
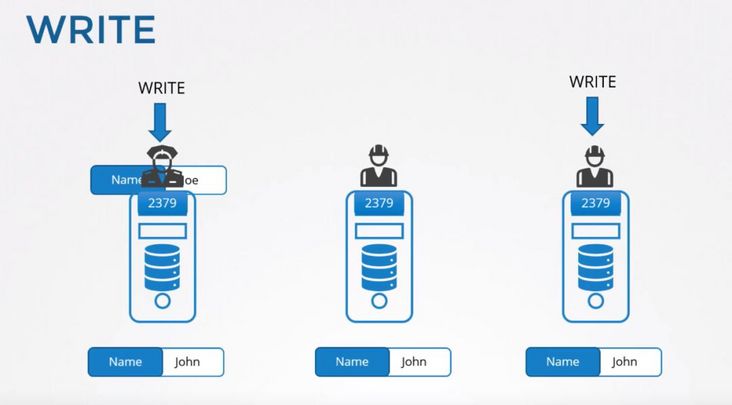
简单点说就是,用户可以对 etcd 集群中的所有节点进行读写,读取非常简单因为每个节点保存的数据是强一致的。对于写入来说,etcd 集群中的节点会选举出 Leader 节点,如果写入请求来自 Leader 节点即可直接写入然后 Leader 节点会把写入分发给所有 Follower,如果写入请求来自其他 Follower 节点那么写入请求会给转发给 Leader 节点,由 Leader 节点写入之后再分发给集群上的所有其他节点。
下面的图示中 1、3 节点都有写入请求,节点 1 为 Leader 所以 3 的写入请求会转发给 1,写入完成后再同步给所有节点。

#如何选举 Leader 节点
假设集群中有三个节点,集群启动之初节点中并没有被选举出的 Leader。
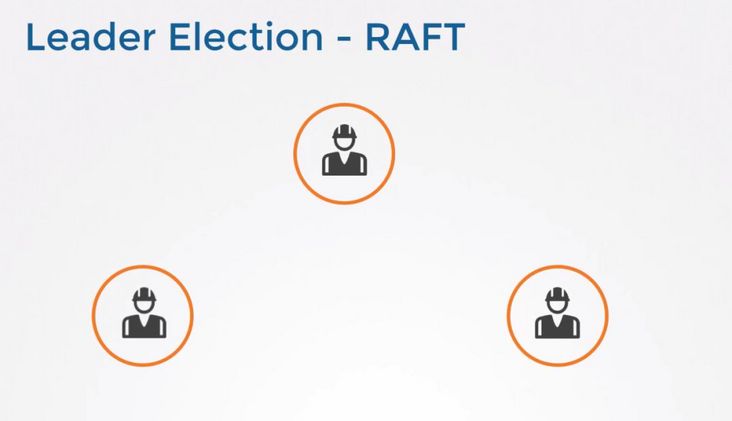
Raft 算法使用随机 Timer 来初始化 Leader 选举流程。比如说在上面三个节点上都运行了 Timer(每个 Timer 的持续时间是随机的),第一个节点率先完成了 Timer,随后它就会向其他两个节点发送成为 Leader 的请求,其他节点接收到请求后会以投票回应然后第一个节点被选举为 Leader。
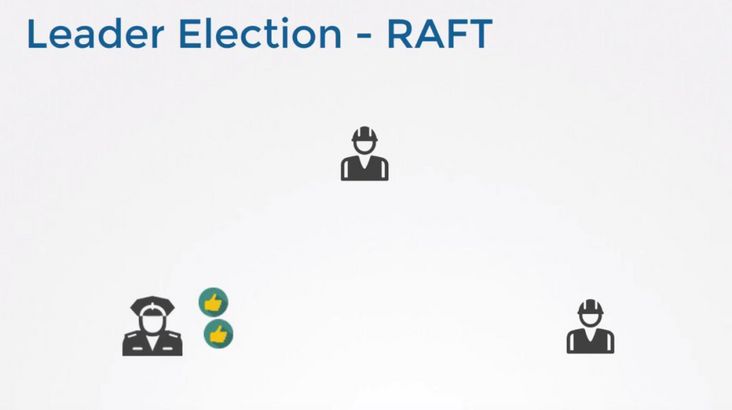
成为 Leader 后,该节点会以固定时间间隔向其他节点发送通知,确保自己仍是 Leader。有些情况下当 Follower 们收不到 Leader 的通知后,比如说 Leader 节点宕机或者失去了连接,其他节点会重复之前选举过程选举出新的 Leader。
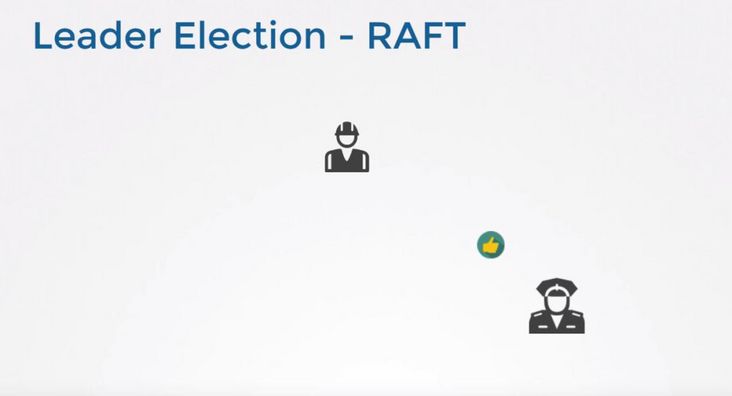
#判断写入是否成功
etcd 认为写入请求被 Leader 节点处理并分发给了多数节点后,就是一个成功的写入。如何界定多数节点呢?很简单,假设总结点数是 N,那么多数节点 Majority=N/2+1,不过在 etcd 中使用的术语是 Quorum而不是 Majority。所以界定多数节点的公式是 Quorum=N/2+1。
#关于节点数的最佳实践

关于如何确定 etcd 集群应该有多少个节点的问题,上图的左侧的图表给出了集群中节点总数 (Instances) 对应的 Quorum 数量,用 Instances 减去 Quorom 就是集群中容错节点(允许出故障的节点)的数量。
所以在集群中推荐的最少节点数量是 3 个,因为 1 和 2 个节点的容错节点数都是 0,一旦有一个节点宕掉整个集群就不能正常工作了。
当决定集群中节点的数量时,强烈推荐奇数数量的节点,比如下图表中高亮的那几个选项。

具体来说,6 个节点的集群它的容错能力并没有比 5 个节点的好,他们的容错节点数一样,一旦容错节点超过 2 后,由于 Quorum 节点数小于 4 整个集群也变为不可用的状态了。
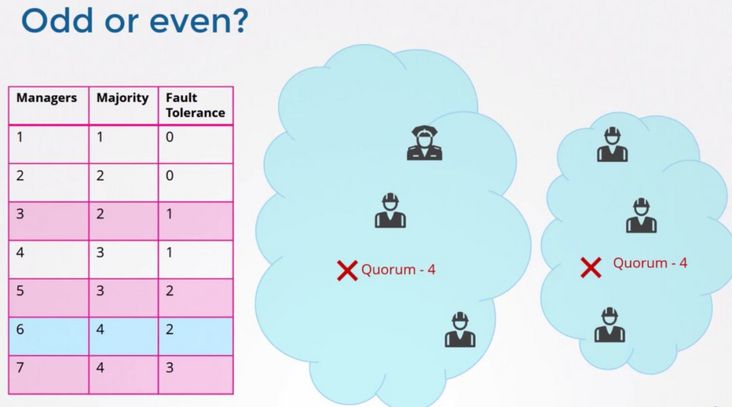
所以在决定集群中的节点数时,奇数要优于偶数。
由于 etcd 之前接触的不多网上成体系资料也比较少一开始理解起来有些困难,最近看了不少文章同时偶然在 Youtube 上发现了一个介绍 etcd 入门的视频,觉得很好。文中的图片大部分都是来自视频的截图,推荐能访问油管的同学都去看看,比看我这里的文章更易懂。如果英语听力不太好的同学可以先看看我的文章再去油管上看视频。
视频链接 https://www.youtube.com/watch...
